Language Models Scale Reliably with Over-Training and on Downstream Tasks
Mar 14, 2024·,,,,,,,,,,,,,,,,,,,,,,·
0 min read
Samir Yitzhak Gadre
Georgios Smyrnis
Vaishaal Shankar
Suchin Gururangan
Mitchell Wortsman
Rulin Shao
Jean Mercat
Alex Fang
Jeffrey Li
Sedrick Keh
Rui Xin
Marianna Nezhurina
Igor Vasiljevic
Jenia Jitsev
Alexandros G. Dimakis
Gabriel Ilharco
Shuran Song
Thomas Kollar
Yair Carmon
Achal Dave
Reinhard Heckel
Niklas Muennighoff
Ludwig Schmidt
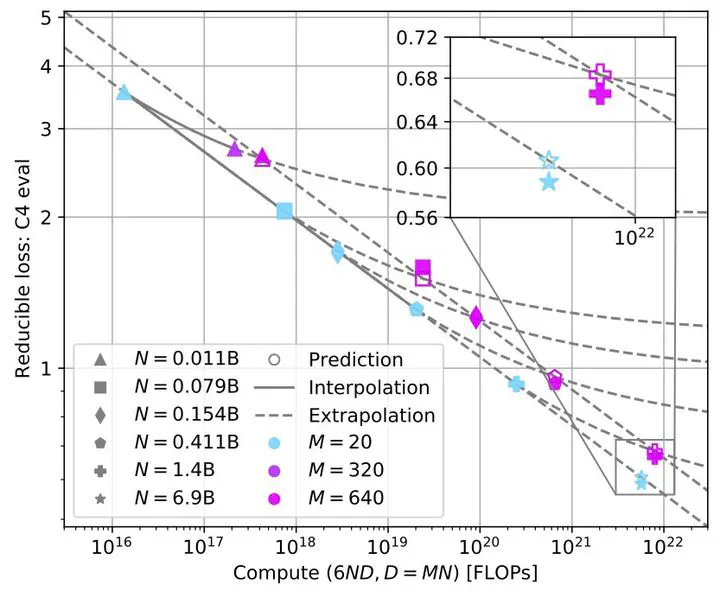 Visualization of scaling laws in over-trained models.
Visualization of scaling laws in over-trained models.Abstract
Scaling laws guide the development of language models, but gaps exist between scaling studies and real-world model training and evaluation. Models are often over-trained to reduce inference costs, and scaling laws predict loss rather than downstream task performance. We create a testbed of 104 models, training them with various tokens and data distributions, to study scaling in the over-trained regime. We find consistent power laws in scaling and predict downstream task performance via a power law relationship with perplexity. Our experiments are available at
.
Publication
In NeurIPS 2024