DataComp-LM: In Search of the Next Generation of Training Sets for Language Models
Jun 17, 2024·,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,·
0 min read
Jeffrey Li
Alex Fang
Georgios Smyrnis
Maor Ivgi
Matt Jordan
Samir Gadre
Hritik Bansal
Etash Guha
Sedrick Keh
Kushal Arora
Saurabh Garg
Rui Xin
Niklas Muennighoff
Reinhard Heckel
Jean Mercat
Mayee Chen
Suchin Gururangan
Mitchell Wortsman
Alon Albalak
Yonatan Bitton
Marianna Nezhurina
Amro Abbas
Cheng-Yu Hsieh
Dhruba Ghosh
Josh Gardner
Maciej Kilian
Hanlin Zhang
Rulin Shao
Sarah Pratt
Sunny Sanyal
Gabriel Ilharco
Giannis Daras
Kalyani Marathe
Aaron Gokaslan
Jieyu Zhang
Khyathi Chandu
Thao Nguyen
Igor Vasiljevic
Sham Kakade
Shuran Song
Sujay Sanghavi
Fartash Faghri
Sewoong Oh
Luke Zettlemoyer
Kyle Lo
Alaaeldin El-Nouby
Hadi Pouransari
Alexander Toshev
Stephanie Wang
Dirk Groeneveld
Luca Soldaini
Pang Wei Koh
Jenia Jitsev
Thomas Kollar
Alexandros G. Dimakis
Yair Carmon
Achal Dave
Ludwig Schmidt
Vaishaal Shankar
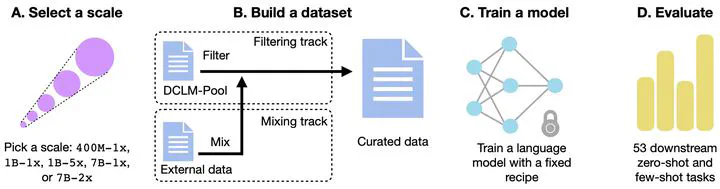 Visualization of data curation strategies in DCLM.
Visualization of data curation strategies in DCLM.Abstract
We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments aimed at improving language models. DCLM includes a standardized corpus of 240T tokens from Common Crawl, effective pretraining recipes using the OpenLM framework, and a suite of 53 downstream evaluations. We emphasize data curation strategies like deduplication, filtering, and data mixing across model scales from 412M to 7B parameters. Our baseline model, DCLM-Baseline, achieves a 64% 5-shot accuracy on MMLU, showing a significant improvement over previous open-data models while requiring less compute. Our findings underline the importance of dataset design in training language models.