A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
Jul 7, 2025·,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,·
0 min read
TRI LBM Team
Jose Barreiros
Andrew Beaulieu
Aditya Bhat
Rick Cory
Eric Cousineau
Hongkai Dai
Ching-Hsin Fang
Kunimatsu Hashimoto
Muhammad Zubair Irshad
Masha Itkina
Naveen Kuppuswamy
Kuan-Hui Lee
Katherine Liu
Dale McConachie
Ian McMahon
Haruki Nishimura
Calder Phillips-Grafflin
Charles Richter
Paarth Shah
Krishnan Srinivasan
Blake Wulfe
Chen Xu
Mengchao Zhang
Alex Alspach
Maya Angeles
Kushal Arora
Vitor Campagnolo Guizilini
Alejandro Castro
Dian Chen
Ting-Sheng Chu
Sam Creasey
Sean Curtis
Richard Denitto
Emma Dixon
Eric Dusel
Matthew Ferreira
Aimee Goncalves
Grant Gould
Damrong Guoy
Swati Gupta
Xuchen Han
Kyle Hatch
Brendan Hathaway
Allison Henry
Hillel Hochsztein
Phoebe Horgan
Shun Iwase
Donovon Jackson
Siddharth Karamcheti
Sedrick Keh
Joseph Masterjohn
Jean Mercat
Patrick Miller
Paul Mitiguy
Tony Nguyen
Jeremy Nimmer
Yuki Noguchi
Reko Ong
Aykut Onol
Owen Pfannenstiehl
Richard Poyner
Leticia Priebe Mendes Rocha
Gordon Richardson
Christopher Rodriguez
Derick Seale
Michael Sherman
Mariah Smith-Jones
David Tago
Pavel Tokmakov
Matthew Tran
Basile Van Hoorick
Igor Vasiljevic
Sergey Zakharov
Mark Zolotas
Rares Ambrus
Kerri Fetzer-Borelli
Benjamin Burchfiel
Hadas Kress-Gazit
Siyuan Feng
Stacie Ford
Russ Tedrake
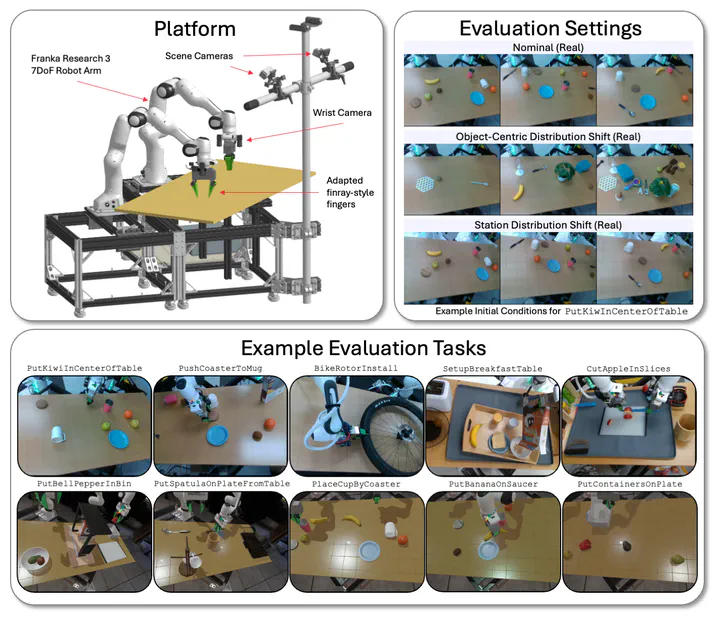 Large Behavior Models (LBMs) for multitask dexterous robot manipulation with rigorous evaluation pipeline.
Large Behavior Models (LBMs) for multitask dexterous robot manipulation with rigorous evaluation pipeline.Abstract
Robot manipulation has seen tremendous progress in recent years, with imitation learning policies enabling successful performance of dexterous and hard-to-model tasks. Concurrently, scaling data and model size has led to the development of capable language and vision foundation models, motivating large-scale efforts to create general-purpose robot foundation models. While these models have garnered significant enthusiasm and investment, meaningful evaluation of real-world performance remains a challenge, limiting both the pace of development and inhibiting a nuanced understanding of current capabilities. In this paper, we rigorously evaluate multitask robot manipulation policies, referred to as Large Behavior Models (LBMs), by extending the Diffusion Policy paradigm across a corpus of simulated and real-world robot data. We propose and validate an evaluation pipeline to rigorously analyze the capabilities of these models with statistical confidence. We compare against single-task baselines through blind, randomized trials in a controlled setting, using both simulation and real-world experiments. We find that multi-task pretraining makes the policies more successful and robust, and enables teaching complex new tasks more quickly, using a fraction of the data when compared to single-task baselines. Moreover, performance predictably increases as pretraining scale and diversity grows.
Type
Publication
arXiv preprint