Linearizing Large Language Models
May 14, 2024·,,,,,,·
0 min read
Jean Mercat
Igor Vasiljevic
Sedrick Keh
Kushal Arora
Achal Dave
Adrien Gaidon
Thomas Kollar
 Graphical representation of SUPRA linearization strategy.
Graphical representation of SUPRA linearization strategy.Abstract
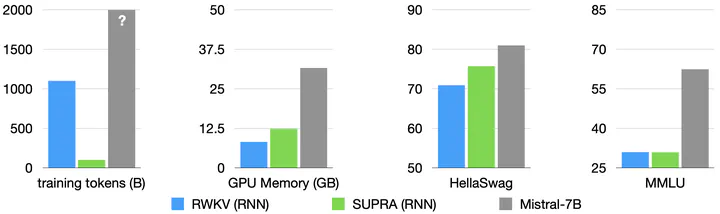
We propose Scalable UPtraining for Recurrent Attention (SUPRA), a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with minimal compute. This approach leverages pre-trained transformers’ strong performance while significantly reducing training costs. SUPRA demonstrates competitive performance on benchmarks but shows limitations in in-context learning and long-context tasks. Our code and models are available at
.
Publication
In COLM (under review)